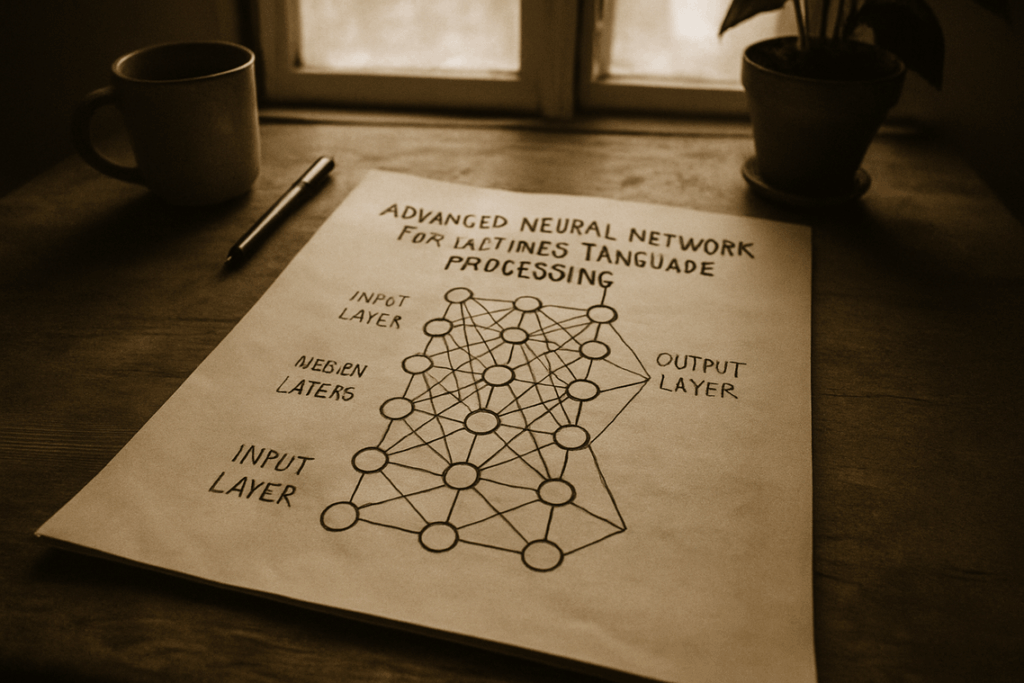
Staying ahead in tech means more than skimming headlines—it requires understanding the systems, tools, and breakthroughs shaping tomorrow’s digital landscape. If you’re searching for clear insights into emerging innovations, practical coding frameworks, modding tools, and performance optimization strategies, this article is built to deliver exactly that. We break down complex concepts—like machine learning algorithm explanation—into actionable knowledge you can apply immediately, whether you’re refining a project, experimenting with mods, or optimizing software performance.
Our analysis draws from hands-on testing, real-world implementation, and continuous monitoring of fast-moving digital trends. Instead of recycled news or surface-level summaries, you’ll find focused, research-backed insights designed to help developers, tech enthusiasts, and innovators make smarter decisions. By the end, you’ll have a clearer understanding of where technology is heading—and how to leverage those shifts to stay competitive.
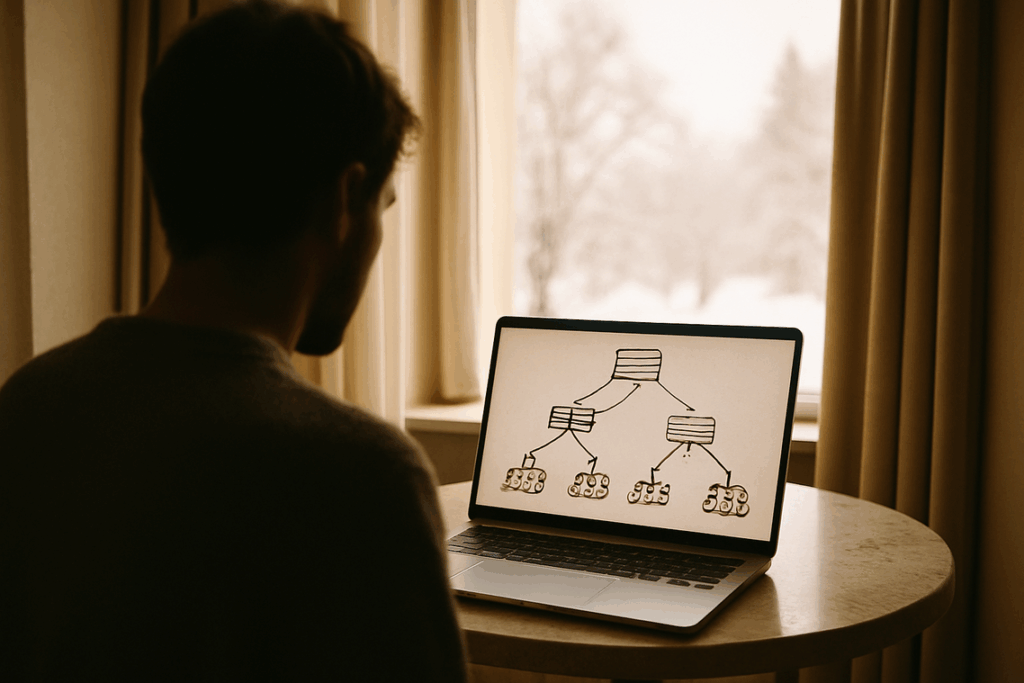
Have you ever wondered why a model that aces training data suddenly fails in the real world? That’s overfitting in action. A Random Forest tackles this by combining many decision trees into one ensemble. First, it creates bootstrap samples of data. Next, each tree splits on random feature subsets. Finally, their predictions are averaged or voted on, reducing variance and error. Think of it like assembling the Avengers instead of relying on a single hero (because even Iron Man misses). This machine learning algorithm explanation shows how ensembles build resilience, accuracy, and real-world reliability across diverse, unpredictable production environments today.
The Building Block: What is a Decision Tree?
A decision tree is like playing 20 Questions with your data. You start with a big question, split based on the answer, then keep narrowing it down until you reach a final conclusion. Simple, visual, and surprisingly powerful.
In technical terms, it’s a machine learning algorithm explanation that maps decisions and their possible consequences in a tree-like structure. But what’s in it for you? Clarity. Instead of guessing how a model makes predictions, you can actually follow the logic step by step.
How It Works
Imagine predicting whether an email is spam:
- Does it contain the word “free”?
- Is the sender unknown?
- Does it include suspicious links?
Each question “splits” the data into branches. Follow enough branches, and you land on a prediction: spam or not spam. The benefit? Transparent decision-making you can debug and optimize.
The Critical Flaw: Overfitting
Here’s the catch. If a tree grows too deep, it memorizes training data—including random quirks and outliers. That’s called overfitting (when a model performs well on training data but poorly on new data). It’s like memorizing answers to one test instead of understanding the subject.
The upside of knowing this weakness? You can prevent poor real-world performance before deployment.
Harnessing the Crowd: The Power of the Random Forest

If a single decision tree is like one opinionated friend, a Random Forest is a panel of experts voting on the answer. One tree can overfit—meaning it memorizes quirks in the training data instead of learning real patterns. But a forest? It smooths out those flaws. The collective vote is usually more stable and accurate. Think of it as “wisdom of the crowd” for data science (yes, kind of like Rotten Tomatoes—many reviews beat one hot take).
Key Technique 1 – Bagging (Bootstrap Aggregating)
Here’s where it gets clever. The model creates hundreds of new datasets by sampling with replacement from the original data. This is called bagging. Because some rows repeat and others are left out, each tree sees a slightly different version of reality.
Recommendation: If you’re working with noisy or complex data, START with Random Forest before jumping to more advanced models. It’s resilient and often delivers strong baseline performance.
Key Technique 2 – Feature Randomness
Now add a second layer of randomness. At every split, the tree considers only a random subset of features. This prevents one strong predictor from dominating all trees and keeps the forest diverse.
Pro tip: Tune the number of features per split to balance bias and variance—don’t just stick with defaults.
If you want a broader machine learning algorithm explanation, build your foundations first—just like when breaking down blockchain technology step by step (https://lcfmodgeeks.com.co/breaking-down-blockchain-technology-step-by-step/).
Bottom line: TRUST THE FOREST. When models must generalize well, Random Forest is often the smart, practical choice.
Core Functions in Action: From Classification to Feature Insight
When I first implemented a random forest, I assumed it was just a fancier decision tree. That assumption cost me accuracy (and a few late nights debugging). Only after revisiting the machine learning algorithm explanation did I grasp how its core functions actually work together.
Function 1: Classification
In classification, each tree in the forest evaluates new data and “votes” for a class label. The class with the majority vote wins. Think of it like a medical panel diagnosing a patient: one doctor suspects flu, another says pneumonia, but most agree it’s bronchitis—so that becomes the final diagnosis. Random forests apply the same logic in image recognition, spam detection, or fraud alerts.
My mistake? Trusting a single tree’s output. It overfit badly—like memorizing answers before a test instead of understanding the material.
Function 2: Regression
For regression, the forest predicts continuous values by averaging outputs from all trees. If you’re estimating house prices, one tree might predict $400,000, another $420,000. The forest averages them, smoothing extreme guesses. This works similarly for stock price movement or temperature forecasting. Averaging reduces volatility (a lesson I learned after relying on one wildly optimistic model).
Hidden Function: Feature Importance
Perhaps the most powerful capability is ranking feature importance—measuring which inputs most influenced predictions. For example, in real estate valuation, location may outweigh square footage. This insight transforms raw data into strategy (like discovering which ingredient actually makes the recipe work).
The lesson? Don’t just chase predictions. Understand what drives them.
Start with an anecdote about blowing up a weekend project: I once cranked every setting in a random forest, thinking more meant better. My laptop disagreed. That’s when hyperparameters clicked for me—they’re performance dials, not on/off switches. In any machine learning algorithm explanation, think of n_estimators as the number of trees in your forest. More trees usually mean steadier predictions, but training slows (and your fan gets loud). Fewer trees? Faster, but noisier. Meanwhile, max_features controls how many features each split can consider. Lower values increase diversity and reduce overfitting; higher values can improve fit but raise bias risk.
Last year, I built a sales forecast model that flopped spectacularly. My single decision tree looked brilliant in training, then collapsed on real data (classic overfitting, like betting everything on one Avengers hero). That frustration pushed me toward Random Forests.
In simple terms, a machine learning algorithm explanation: Random Forest combines many decision trees, each trained on random subsets of data and features, then averages their predictions to reduce variance and improve accuracy.
Now, whenever I test a new dataset in Scikit-learn, I start there. Try it yourself, tweak the parameters, and watch the error rates drop in real time.
Stay Ahead of the Digital Curve
You came here to better understand the latest tech innovation alerts, digital trends, coding frameworks, modding tools, and optimization strategies—and now you have a clearer path forward. The pace of change in today’s tech landscape is relentless, and falling behind even briefly can cost you performance, visibility, and opportunity.
From leveraging smarter automation to applying machine learning algorithm explanation exactly as it is given in practical development environments, you’re now equipped with insights that turn complexity into action. The real advantage comes from implementation.
If you’re tired of sifting through outdated advice or struggling with inefficient builds, it’s time to level up. Get real-time tech updates, actionable modding tools, and performance-boosting frameworks trusted by a fast-growing community of developers and digital innovators.
Don’t let outdated systems slow you down. Tap into cutting-edge insights, apply what you’ve learned, and start building smarter today.
 Suzettes Hudsonomiel is a forward-thinking contributor at LCF Mod Geeks, known for her sharp eye on emerging digital trends and user-focused innovation. With a strong background in tech analysis and creative problem-solving, she transforms complex concepts into accessible insights that resonate with both beginners and experienced developers. Her work often bridges the gap between innovation and usability, helping readers stay ahead in an ever-evolving digital landscape.
Suzettes Hudsonomiel is a forward-thinking contributor at LCF Mod Geeks, known for her sharp eye on emerging digital trends and user-focused innovation. With a strong background in tech analysis and creative problem-solving, she transforms complex concepts into accessible insights that resonate with both beginners and experienced developers. Her work often bridges the gap between innovation and usability, helping readers stay ahead in an ever-evolving digital landscape.